|
The disappearing web: Information decay is eating away our history One of the characteristics of the modern media age — at least for anyone who uses the web and social media a lot — is that we are surrounded by vast clouds of rapidly changing information, whether it’s blog posts or news stories or Twitter and Facebook (s fb) updates. That’s great if you like real-time content, but there is a not-so-hidden flaw — namely, that you can’t step into the same stream twice, as Heraclitus put it. In other words, much of that information may (and probably will) disappear as new information replaces it, and small pieces of history wind up getting lost. According to a recent study, which looked at links shared through Twitter about news events like the Arab Spring revolutions in the Middle East, this could be turning into a substantial problem. The study, which MIT’s Technology Review highlighted in a recent post by the Physics arXiv blog, was done by a pair of researchers in Virginia, Hany SalahEldeen and Michael Nelson. They took a number of recent major news events over the past three years — including the Egyptian revolution, Michael Jackson’s death, the elections and related protests in Iran and the outbreak of the H1N1 virus — and tracked the links that were shared on Twitter about each. Following the links to their ultimate source showed that an alarming number of them had simply vanished. 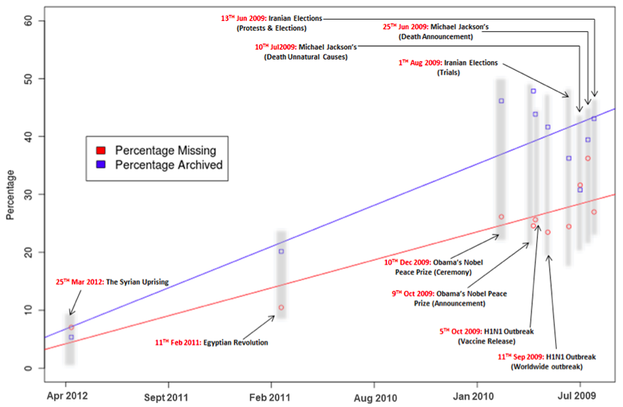 After two and a half years, 30 percent had disappeared In fact, the researchers said that within a year of these events, an average of 11 percent of the material that was linked to had disappeared completely (and another 20 percent had been archived), and after two-and-a-half years, close to 30 percent had been lost altogether and 41 percent had been archived. Based on this rate of information decay, the authors predicted that more than 10 percent of the information about a major news event will likely be gone within a year, and the remainder will continue to vanish at the rate of .02 percent per day. It’s not clear from the research why the missing information disappeared, but it’s likely that in many cases blogs have simply shut down or moved, or news stories have been archived by providers who charge for access (something that many newspapers and other media outlets do to generate revenue). But as the Technology Review post points out, this kind of information can be extremely valuable in tracking how historical events developed, such as the Arab Spring revolutions — which the researchers note was the original impetus for their study, since they were trying to collect as much data as possible for the one-year anniversary of the uprisings. Other scientists, and particularly librarians, have also raised red flags in the past about the rate at which digital data is disappearing. The National Library of Scotland, for example, recently warned that key elements of Scottish digital life were vanishing into a “black hole,” and asked the government to fast-track legislation that would allow libraries to store copies of websites. Web pioneer Brewster Kahle is probably the best known digital archivist as a result of his Internet Archive project, which keeps copies of websites dating back to the early days of the web (Kahle also has a related project called the Open Library). Getting access to social data is not easy Although the Virginia researchers didn’t deal with it as part of their study, a related problem is that much of the content that gets distributed through Twitter — not just websites that are linked to in Twitter posts, but the content of the posts themselves — is difficult and/or expensive to get to. Twitter’s search is notoriously unreliable for anything older than about a week, and access to the complete archive of your tweets is only provided to those who can make a special case for needing it, such as Andy Carvin of National Public Radio (who is writing a book about the way he chronicled the Arab Spring revolutions). As my colleague Eliza Kern noted in a recent post, an external service called Gnip now has access to the full archive of Twitter content, which it will provide to companies for a fee. And Twitter-based search and discovery engine Topsy also has an archive of most of the full “firehose” of tweets — although it focuses primarily on content that is retweeted a lot — and provides that to companies for analytical purposes. But neither can be linked to easily for research or historical archiving purposes. The Library of Congress also has an archive of Twitter’s content, but it isn’t easily accessible and it’s not clear whether new content is being added or not. Twitter has talked about providing a service that would let users download their tweets at some point, but it hasn’t said when such a thing would be available — and even if users did create their own archive in this way (or by using tools like Thinkup from former Lifehacker editor Gina Trapani) it would be difficult to link those in a way that would provide the kind of connected historical information the Virginia study is describing. And it’s not just Twitter: there is no easy way to get access to an archive of Facebook posts either, although users in Europe can request access to their own archive as a result of a legal ruling there. For better or worse, much of the content flowing around us seems to be just as insubstantial as the clouds that it is hosted in, and the existing tools we have for trying to capture and make sense of it simply aren’t up to the task. The long-term social effects of this digital amnesia remain to be seen. https://gigaom.com/2012/09/19/the-disappearing-web-information-decay-is-eating-away-our-history/
0 Comments
Leave a Reply. |

Mister Camel
Bookmark this site for news, entertainment and other information. Don't forget to comment and tell others. Archives
May 2018
Categories
|
 RSS Feed
RSS Feed
